数据存储与检索 #
数据结构 #
哈希索引 #
【图:哈希索引】
适合内存,不适合磁盘。对于磁盘而言,追加效率更高。而哈希索引需要频繁的随机读取,磁盘效率很低。
实现中需要考虑的问题:
- 文件格式:使用二进制而不是字符串
- 删除记录(墓碑):合并日志段时需要识别来丢弃指定记录
- 崩溃恢复:用快照来提高启动速度
- 部分写入记录:校验
- 并发控制:写入可依赖写入原子性,数据文件段会被不同的线程同时读取(读锁)
SSTable1 和 LSM-Tree2 #
SSTable (Sorted String Table)排序字符串表:key-value 对按照 key 排序。
【图:SSTable】
相比哈希索引,有以下优势:
- 合并段简单高效,即使在文件比可用内存大的情况下:因为 kv 有序,并发读取+多指针比对即可完成合并。
- 查找特定的 key 成本更低:不用在内存中保存所有的索引,内存中可以存储一个稀疏索引(kv 有序,可以做比对,找到相应区间)(注:此处跟二分查找仍有差别,因为 key 在实际中并不时固定长度的),每几千字节,增加一个 key 即可。 【图:内存索引+SSTable】
- kv 块在被写到磁盘块前,进行合并压缩后,并将该块的开头存储至内存的稀疏索引中:节省磁盘空间,减少 I/O 带宽占用。
在内存中维护内存表:可使用 红黑树 或 AVL 树,它们有 按任意顺序插入键并以排序后的顺序读取 的性质。
使用 SSTable 的存储引擎大致工作流程:
- 写入时,将内容添加到内存的平衡树数据结构中(即内存表)。
- 当内存表大于写入阈值(一般为几 MB)后,将其作为 SSTable 写入磁盘(此时写入较高效,因为内存表已经维护了 kv 的顺序)。
- 读取时,首先尝试在内存表中寻找 key,然后从新的磁盘段至最老的磁盘段为顺序,逐个检索。
- 有一个后台进程,周期性执行段合并和压缩过程,合并多个段文件,降低存储占用,并删除被覆盖/删除的值。
这个流程无法处理在突然宕机的情况下,未写入磁盘的内存表数据丢失的问题。因此,还需要一个额外的写入日志,每次写入操作都直接追加到该日志中。它的唯一目的就是在内存崩溃之后恢复内存表,因此在内存表写入 SSTable 之后,这部分日志就可以丢弃了。
使用项目:LevelDB、RocksDB、Cassandra、HBase 等。
性能优化:
- 查找 key 不存在,使用布隆过滤器加速。
- 合并压缩策略:大小分级 和 分层压缩。
由于磁盘是顺序写入的, 因此该法能支持较高的写入吞吐量。
因此,也可以称日志结构的存储引擎,是通过系统地将磁盘上的随机访问(B-tree)写入转换为了顺序写入。由于当下存储系统的特性,这样的方式能够获得较高的写入吞吐量。
优点:
- LST-Tree 有较低的写放大,因此能够承载比 B-tree 更高的写入量。
缺点:
- 压缩过程会影响到读写操作,使得性能不确定。
- 压缩过程会与写操作抢占写带宽。
B-tree #
【图:B-tree】
特点:
- 按 key 排序的 key-value 对(这点与 LSM-Tree 一致)
- 将数据库分解成固定大小的块/页(传统上为 4KB)页是读写的最小单元。
- 每个页面都使用地址/位置进行标识,通过这些页面引用构造出一个树状页面。
读取/修改:沿着页引用不断查找到目标 key,获取/修改 value。
写入:找到范围包含新 key 的页,若该页无额外空间,需要做 分裂页面 操作(将其分裂成两个半满的页,同时更新上层索引)。
具有 n 个键的(平衡的) B-tree 总是有 $O(logn)$ 深度(分支因子为 500 的 4KB 页的四级树存储高达 256 TB)。
由于 B-tree 直接写入磁盘,因此存在若在写入部分页后发生宕机事件,会导致索引被破坏(产生孤儿页)。因此常见实现中会加入预写日志(WAL, write-ahead log)3 来恢复 B-tree 到最近的状态。
多个线程同时访问 B-tree,需要进行并发控制:使用锁存器(轻量级的锁)【这是啥?】来保护树的数据结构。
常见优化:
- 写时复制:修改也被写入不同的位置,树的父页新版本被创建出来,并指向新位置(可不用覆盖页和 WAL 来做崩溃恢复)。
- 保留 key 的缩略信息:让更多的 key 能被压入到页中(B+ 树)。
- 邻叶子页顺序保存:提高 I/O 性能,但是随着树的增长,这是很难的事。
- 添加额外引用到树中:如同级兄弟形成同级链表,可以顺序扫描键。
- 分形树:减少磁盘寻道。
相比于 LSM-Tree 来说,B-tree 读取速度更快。
缺点:
- 写入过程繁琐,需要维护 WAL 和页面。并且每次修改都以整个页面为单位,写入性能不高。
其他索引 #
索引可以增加查询速度,但是需要额外存储,且所有索引都会额外增加写入开销。
二级索引 #
可以基于 key-value 构建,key 不一定唯一。
构建方法:
- 索引中的 value 成为匹配行标识符的列表(全文索引中的 position list)。
- 追加行标识符使 key 唯一。
B-tree 和 LSM-Tree 都可以用作二级索引。
堆文件 #
索引中的 value 存储的是对其他地方存储的行的引用(并不以特定的顺序存储数据),而不是实际行内容。这种方式被称为:堆文件(非聚集索引)。
堆文件在更新 value 而不更新 key 的时候非常高效。但若 value 较大,存储目标需要重新创建,则要重新将该索引的所有 value 都更新为新的地址引用(或在旧堆位置保留一个间接指针)。
聚集/聚簇索引 #
即:将索引行直接存储到索引中。
MySQL 的 InnoDB 存储引擎使用该方式:表主键始终是聚集索引(聚簇索引),二级索引直接引用主键。
覆盖索引/包含列的索引 #
是聚集索引与非聚集索引的折中设计,特点为:
- 索引中保存了一些表的列值。
- 支持指通过索引即可回答“简单查询”(索引覆盖了查询)。
多列索引 #
级联索引 #
级联索引:将一列追加到另一列,将几个字段简单的组成一个 key。
如 (lastname, firstname) 的级联索引:能搜索特定 lastname 数据,能搜索特性 lastname-firstname 数据,但不能搜索特定 firstname 数据。
适用于地理位置等多维搜索。
R-tree #
专门的空间索引。
全文搜索 #
通常支持对一个单词的所有同义词进行查询,并忽略单词语法上的变体。
Lucene 对词典使用类似 SSTable 的结构,因此需要一个小的内存索引。
这个内存索引在 Lucene 中是 key 的字符序列的有限状态自动机(DFA),类似于字典树。它可以转换为 Levenshtein 自动机【这是什么?】,支持在给定编辑距离4内高效搜索单词。
内存中保存所有内容 #
内存数据库更快的原因是:它们可以避免使用写磁盘的格式对内存数据结构编码的开销(即序列化/反序列化)。
内存数据库能够提供基于磁盘索引难以实现的数据模型,如 Redis 实现了各种数据结构,都提供了内存数据库的相关接口,且因为数据都保存在内存中,实现比较简单。
事实上,内存数据库架构能够支撑远高于可用内存的数据集,而不会导致以磁盘为中心架构的开销。
反缓存方法:当没有足够的内存时,通过将最近最少使用的数据从内存写入磁盘,在未来再次被访问时重新加载到内存中。
未来 NVM(非易失性存储,non-volatile memory)的普及,会影响到存储引擎的设计。
事务处理和分析处理 #
事务处理只意味着允许客户端进行低延迟读写和写入,并不一定具有 ACID 属性。
OLTP 和 OLAP #
在线事务处理 OLTP(OnLine Transaction Processing):应用通常使用索引中某些键来查找少量记录,根据用户的输入来插入或更新记录。
在线分析处理 OLAP(OnLine Analytic Processing):分析查询需要扫描大量记录,并计算汇总统计信息(计数/求和/平均值),并不返回原始数据给用户。
对比 OLTP 和 OLAP:
| 属性 | OLTP | OLAP |
|---|---|---|
| 主要读特征 | 基于 key,每次查询返回少量的输入 | 对大量记录进行汇总 |
| 主要写特征 | 随机访问,低延迟写入用户的输入 | 批量导入(ETL)或事件流 |
| 典型使用场景 | 终端用户,通过网络应用 | 内部分析师,为决策提供数据支持 |
| 数据表征 | 最新的数据状态(当前时间点) | 随时间而变化的所有事件历史 |
| 数据规模 | GB ~ TB | TB ~ PB |
| 主要瓶颈 | 磁盘寻道时间(查找请求 key 的数据) | 磁盘带宽(扫描大批数据) |
数据仓库 #
动机:数据管理员(DBA)通常不愿意让业务分析人员在 OLTP 数据库上直接运行临时分析查询,这些查询通常代价很高,需要扫描大量数据集,可能会损害并发执行事务的性能。
数据仓库:单独的数据库,包含公司所有 OLTP 系统的只读副本。会从 OLTP 系统中提取数据(周期性数据转储或连续更新流,extract),并转换为分析友好的模式(transform)执行清理后,导入到数据仓库中(load)。这个过程也被称为 ETL(Extract-Transform-Load)。
星型分析模式 #
该模式的中心是一个“事实表”(fact table):事实表的每一行表示在特定时间发生的事件,列是事件不同的属性值;有些列可能也会引用其他表的外键,(其他表)称为维度表。
事实表中每一行都代表一个事件,因此维度通常代表事件的 5W1H(who, what, where, when, how, why)。
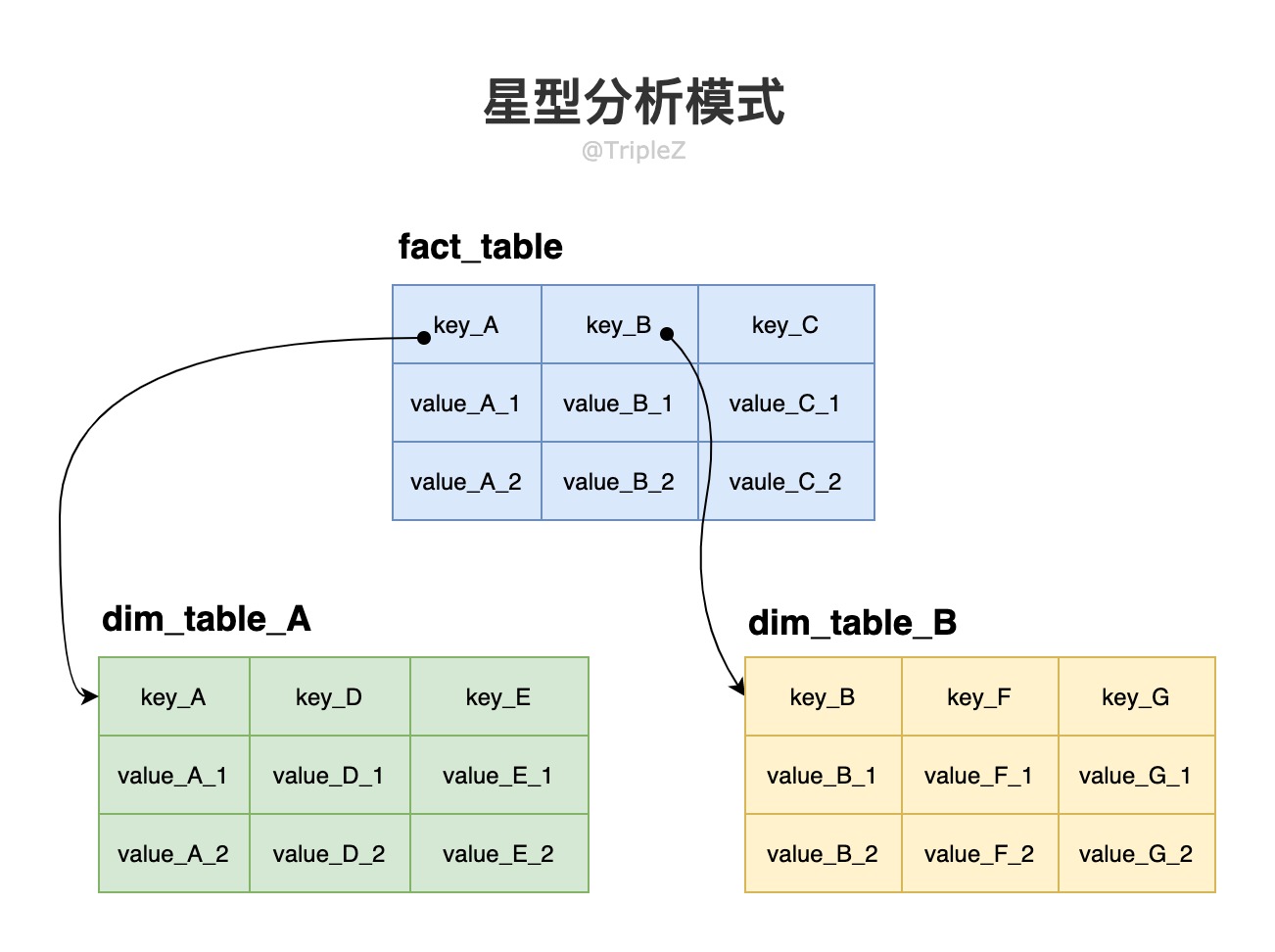
事实表通常非常宽,超过 100 列,甚至几百列。维度表也非常宽,可能包括与分析有关的所有元数据。
雪花型分析模式 #
是星型分析模式的变种,在维度中进一步划分子空间,维度表中继续引用维度表。
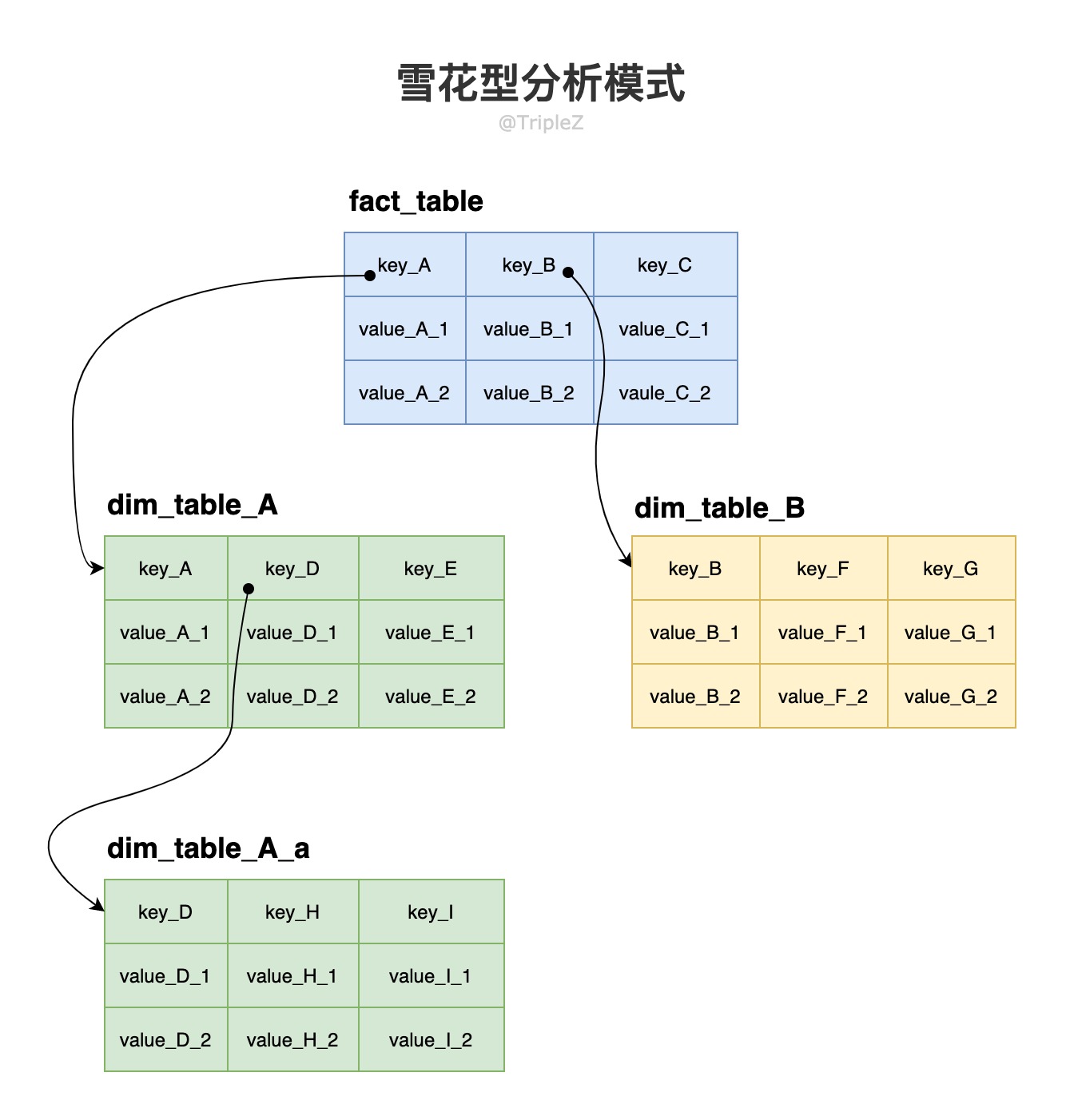
雪花模式更加规范。但对于分析人员而言,星型模式通常是首选,因为其使用更简单。
列式存储 #
动机:事实表中的数据规模非常庞大,且我们经常只需要对其中几列的内容做查询计算,因此,我们不需要将目标行中所有的内容都从磁盘读入内存中。基于这个设想,我们可以通过将每一列的所有值存储在一起,这样读取和解析查询中使用的列,相比于行式存储能够节省大量的工作。
列压缩 #
目的:降低磁盘吞吐量。
数仓中有效的列压缩技术:
-
位图编码(Bitmap):列式存储能够得到一个有 n 个不同值的列。我们可以将其转换为 n 个独立位图 (每个不同的值都有一个位图,每行用一位来代表是否为该值。若该行具有该值,则为 1 ,否则为 0 )。
-
游程编码(Run-length encoding):在位图编码中,如果 n 较大,在大部分位图中会存在大量的 0(稀疏位图),我们可以对位图再进行游程编码,
位图索引很适合数据仓库的查询,若查找指定的值的行数,只需要按位或累加即可。
Cassandra 和 HBase 中,一行中的所有列仍然与行 key 一起存储,且不会使用列压缩,因此它们并不是面向列,而仍然是面向行的。列族的概念只是从 BigTable 继承而来,并不代表其是列式存储。
列式存储中性能提升的方式:
- 提高主存储器带宽到 CPU 缓存带宽的利用率:避免 CPU 分支预测错误和泡沫;使用 SIMD 指令。
- 列式存储本身就能有效利用 CPU 周期:能够将大量压缩的列数据放到 CPU L1/L2 缓存中(类似于 GEMM 的性能优化),使用矢量化处理技术来提升性能。
列存储排序顺序 #
按列来存储数据,也需要对整行进行排序。DBA 可以选择具体排序的 key,这样的好处有很多:
- key 中相近的 value 会在存储中组合在一起,能够提高特性范围的过滤查询效率。
- 排序顺序可以帮助压缩列,如果重复值尽可能能够排列在一起,那么我们就可以用 列压缩 中所提到的压缩方法,极大降低磁盘空间的占用。
- 对第一个 key 排序的压缩效果最强,第二和第三排序 key 比较混乱。
面向列存储的排序中,只有包含 value 的列,通常没有指向数据的指针。
写入列存储 #
由于存在压缩和排序,写入列存储无法使用如 B-tree 这类能就地更新的方法。幸运的是,前面提及的 LSM-Tree,能够很好的处理这种情况:先存入内存,再刷入磁盘。
聚合 #
物化视图:通常被定义为一个标准(虚拟)视图:一个类似表的对象,内容是一些查询的结果5。
在底层数据发生变化时,物化视图也需要跟着更新(因为它是数据的非规范化副本)。而这个特性会影响到数据写入性能,也是为什么 OLTP 系统不经常用物化视图的原因。若有大量聚合读取,物化视图才更有意义。具体是否需要建立物化视图,如何设置物化视图,都需视实际情况而定。
一种常见的物化视图的特殊情况:数据立方体 / OLAP 立方体。它是不同维度分组组成的聚合网格。
一个用于求和的二维的数据立方体:
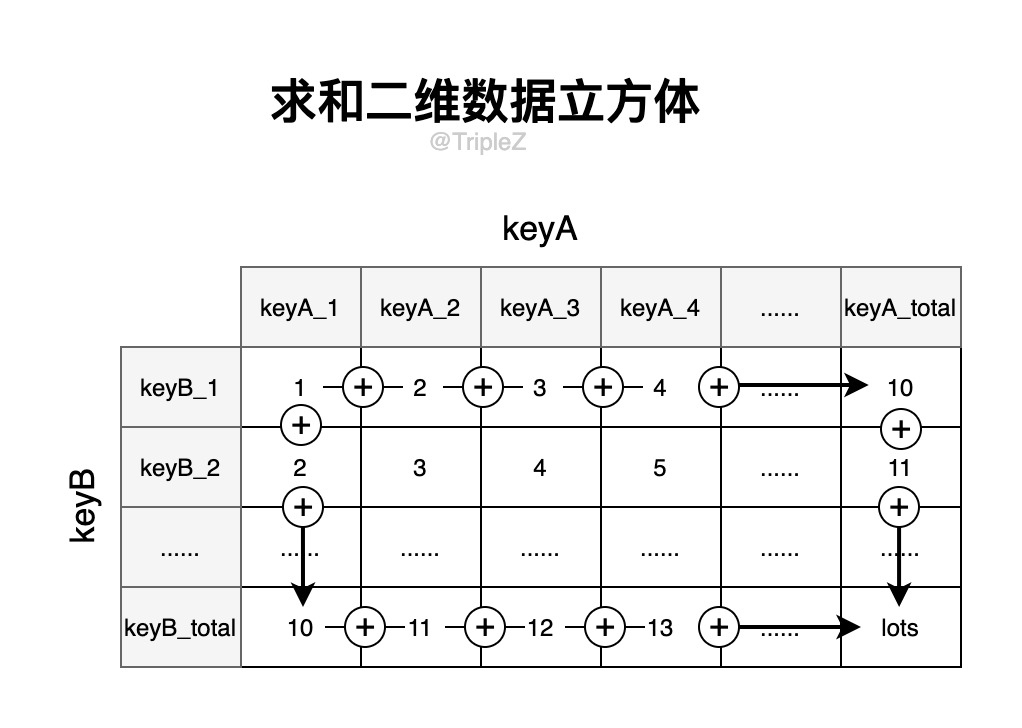
数据立方体优点:由于部分数据已经被提前计算出来,因此某些(能被数据立方体优化的)查询会非常快。
数据立方体缺点:缺乏如原始数据般的灵活性。
结论:大多数数仓都保留尽可能多的原始数据,仅当数据立方体能够对特定查询显著提升性能时,才会采用多维数据聚合的数据立方体。